
На сегодняшний день поисковые системы — это один из самых простых и эффективных способов быстро найти ответ на интересующий вопрос, узнать последние новости или приобрести товар, который очень сложно отыскать в торговой сети. Но давайте посмотрим на поисковую систему глазами владельцев веб-ресурсов. Существуют довольно качественные и полезные сайты, до которых пользователь просто не доходит из-за того, что они и близко не попадают в ТОП-10 и даже ТОП-50 поисковой выдачи.
Порой и отлично оптимизированные ресурсы с прекрасным рейтингом и уровнем доверия поисковых систем могут ранжироваться довольно плохо. Одной из основных причин этого является наличие большого количества дублей и «бесполезных» (с точки зрения поисковых систем) страниц в индексе.
Основным и наиболее оптимальным инструментом для борьбы с дублями всегда был стандарт robots.txt. Основное его предназначение — исключение из индекса нежелательных страниц, что очень актуально для эффективного и результативного продвижения сайта в поисковых системах. Не станем детально останавливаться на теоретическом описании назначения и синтаксиса этого файла. Об этом можно прочитать на англоязычном и русскоязычном тематических ресурсах. Мы же подробно рассмотрим практическую сторону применения этого стандарта при продвижении в поисковой системе Google.
Плюсы
- Запрет на индексирование отдельных страниц, файлов и каталогов.
- Возможность настроить разрешение на индексирование отдельных файлов в каталоге, который закрыт от индексации (указание директивы «Allow» после соответствующей директивы «Disallow»).
- Простота использования в сравнении, например, с мета-тегом <meta name=«robots»> (его необходимо указывать на каждой странице, которую нужно закрыть от индексации, в то время как файл robots.txt позволяет закрывать целые каталоги).
- Возможность закрытия всего сайта от индексации путем указания директивы «Disallow: /» (закрытие тестовой версии перед тем, как «выкатить» обновленный сайт).
© Depositphotos.com/Jaka Vukotič

Минусы
Попадание во второстепенный индекс
Страницы, закрытые от индексации, скорее всего, все равно попадут в индекс Google. В частности, эти страницы можно найти во второстепенном индексе поисковика, сделав запрос с помощью оператора «site:my-site.com» и нажав «Показать скрытые результаты».

Такие страницы в индексе будут иметь соответствующее описание под ссылкой на них:

Как известно, наличие большого количества страниц во второстепенном индексе — это и более медленная индексация сайта со стороны Google, и снижение позиций в результатах поиска за счет того, что на сайте, по мнению поисковика, есть много «бесполезных» для пользователя страниц, и т. п.
Некорректное прочтение файла поисковиком
Еще одним существенным недостатком является то, что Google может некорректно прочитать информацию в файле robots.txt. Из-за этого нормальные страницы также могут попасть во второстепенный индекс.
Например, вот директивы, которые указаны в файле robots.txt сайта, А:
|
1 2 3 |
"]Disallow: /menus/view/223/ Disallow: /admins/ Disallow: /*?* |
А вот ситуация, которая наблюдается в индексе Google при запросе с помощью оператора «site»:
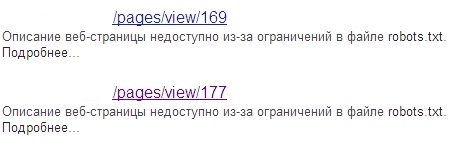
Как следует из содержания файла robots.txt для сайта, А и скриншота индекса поисковой системы, во второстепенном индексе Google присутствуют страницы с сообщением «Описание веб-страницы недоступно из-за ограничений в файле robots.txt». Хотя четко видно, что такие страницы не закрыты от индексации. Кроме того, они отлично оптимизированы, имеют уникальный контент, и наличие их в основном индексе могло бы положительно повлиять на ранжирование сайта в целом.
Советы
Во-первых, с помощью оператора «site» всегда проверяйте наличие нужных страниц в основном индексе. Во-вторых, используйте следующие способы для запрещения индексации отдельных страниц.
- Указывайте в блоке <head> мета-тег <meta name=«robots»>
С помощью этого тега можно полностью закрыть страницы от индексации и запретить поисковому роботу переходить по ссылкам на этой странице:
|
1 |
"]<meta name=«robots» content=«noindex, nofollow»> |
Результат: поисковый робот не проиндексирует содержимое страницы и не будет переходить по ссылкам на этой странице (оптимально будет, например, для закрытия страниц с внешними ссылками на партнеров);
Также <meta name=«robots»> позволяет полностью закрыть страницы от индексации, но разрешить поисковому роботу переходить по ссылкам на этой странице:
|
1 |
"]<meta name=«robots» content=«noindex, follow»> |
Результат: робот не проиндексирует содержимое страницы, но будет переходить по ссылкам на этой странице и индексировать содержание тех страниц, на которые эти ссылки ведут. Оптимально будет для закрытия ненужных страниц фильтрации, сортировки и пагинации. При этом робот будет переходить на страницы товаров и индексировать их содержание.
Недостатком данного способа является то, что страницы, на которых прописан этот мета-тег, не всегда закрыты от индексации. Бывают случаи, когда содержимое таких страниц успешно индексируется Google. В таком случае «для подстраховки» можно прибегнуть к еще одному методу, который описан ниже.
- Указывайте атрибут <link rel=«canonical»> для страниц, дублирующих содержание канонической страницы
Это хорошо работает не только для полных дублей страницы (например, версии для печати), но и для частичных дублей. Например, на сайте есть несколько страниц для одного и того же товара, представленного в разных цветовых вариантах. Оптимально при этом будет выбрать одну из таких страниц как основную (например, товар в наиболее популярной расцветке), а на остальных страницах в атрибуте <link rel=«canonical»> указать ее как каноническую.
- Удаляйте ненужные страницы, которые уже попали в индекс поисковой системы, при помощи инструмента в панели для вебмастеров Google Webmasters Tools: «Удалить URL-адреса»
При помощи этого инструмента можно удалить не только конкретную страницу из индекса Google, но и все страницы в этом каталоге, конкретные изображения или даже весь сайт. Единственный совет: тщательно ознакомьтесь с рекомендациями Google по его использованию.
- «Склеивайте» дубли при помощи 301-го серверного редиректа
Рекомендация: после настройки 301-го редиректа на соответствующие страницы необходимо отправить запрос на индексацию старой страницы через инструмент Google Webmasters Tools «Просмотреть как Googlebot».
В последнее время новые страницы после 301-го редиректа попадают в индекс на протяжении 1–3 дней с момента отправки запроса. Единственный нюанс: лучше не закрывать от индексации старые страницы, ведь тогда поисковый робот не сможет на них попасть и «склеить» с нужной нам страницей.
- Используйте http-заголовок rel=«canonical»
|
1 |
"]«Link: <http://www.<span class="nobr">my-site</span>.com>; rel=«canonical» |
Применение этого способа будет оптимально для различных типов файлов с разнообразными расширениями: .pdf, .xls и др.
Подводя итог, отмечу, что проблема борьбы с дублями всегда была и является актуальной для любого SEO-специалиста. Поэтому не бойтесь экспериментировать, использовать различные варианты борьбы с дублями, оценивать результаты и делать выводы, исходя из практики, а не основываясь на голой теории.